| 丒GCCODE丂夝愅僣乕儖柍偟偩偲僉僣僀偱偡丅 |
| 丒僶僀僫儕僄僨傿僞丂悢楍偐傜撪梕傪夝愅偟偨傝丄僷僞乕儞僥乕僽儖傪嶌傞偺偵巊偄傑偡丅 |
| 丒VisualC++6.0丂僣乕儖嶌惉梡偱偡丅Borland C++ Compiler(僼儕乕)偱戙梡偱偒傑偡丅 |

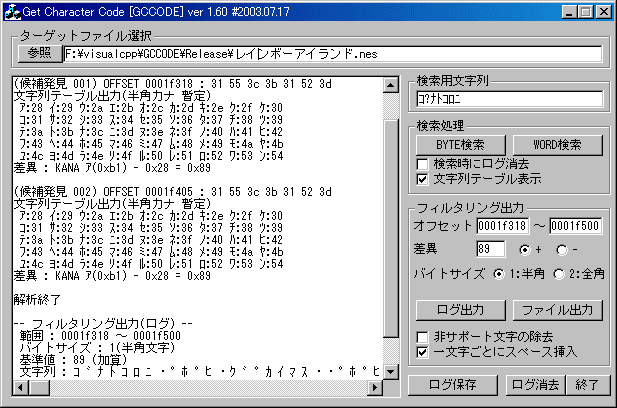
| 夋柺昞帵 | 偙 | 傫 | 側 | 偲 | 偙 | 傠 | 偵 | 丄 | 傎丣 | 傂丣 | 乣 | 偔 | 傫 | 偑 | 偄 | 傑 | 偡 | 丅 | GCCODE偺暥帤楍 | 偙 | 亊 | 側 | 偲 | 偙 | 傠 | 偵 | 亊 | 並傎 | 並傂 | 亊 | 偔 | 亊 | 並偐 | 偄 | 傑 | 偡 | 亊 |
| 暥帤僐乕僪斣崋 | 僥乕僽儖忋偺僆僼僙僢僩 | 暥帤楍 |
| 00乣09 | 00乣12 | 侽侾俀俁係俆俇俈俉俋 |
| 0A乣23 | 14乣46 | 俙俛俠俢俤俥俧俫俬俰俲俴俵俶俷俹俻俼俽俿倀倁倂倃倄倅 |
| 27 | 4E | 僗儁乕僗[丂] |
| 28乣40 | 50乣80 | 偁偄偆偊偍偐偒偔偗偙偝偟偡偣偦偨偪偮偰偲側偵偸偹偺 |
| 41乣55 | 82乣AA | 偼傂傆傊傎傑傒傓傔傕傗備傛傜傝傞傟傠傢傪傫 |
| 57乣61 | AE乣C2 | 傖傘傚偭乣丄丅両丠乽乿 |
| 63 | C5 | 乨 |