update 2003.12.11
プレイステーション版「ぷよぷよSUN決定版」漫才テキストコンバータ
概要
先日、紆余曲折の果てに
ぷよぷよ
など数多くの名作を残したコンパイルが消滅しました。
各人気シリーズはセガ等に権利が移ったものの、やはりコンパイルにしか生み出せない名作が
二度と見られないと思うと、寂しい限りですねぇ・・・。
そこで追悼の意を表し今回の題材は、今までのファミコンシリーズでは無く、
プレイステーションソフト「ぷよぷよSUN決定版(以後ぷよSUN)」です。
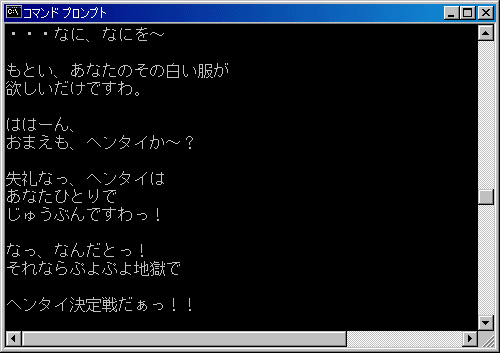
この作品は毎シリーズ「漫才デモ」という、戦闘の合間にキャラ同士の馬鹿話があるのですが、
そのキャラ同士の会話をテキスト変換出力します。
準備
この解析・変換ツール作成には以下のものを使用しました。
・GCCODE
解析ツール無しだとキツイです。
・バイナリエディタ
数列から内容を解析したり、パターンテーブルを作るのに使います。
・VisualC++6.0
ツール作成用です。Borland C++ Compilter(フリー)で代用できます。
・ePSXe
PSエミュレータです。頻繁に内容確認するためリアルタイムセーブは必須です。
解析
まず、今までの作品のように吸出し機でROMデータを吸い出す必要が無いため、
ぷよSUNのCDを直接PCのCD-ROMドライブに挿入し、漫才デモが格納されているファイルを探します。
実機と同時進行しても良いのですが、SaveStateが使えるePSXe等のエミュレータを
活用すれば、とてもスムーズに解析を行うことができます。
ちなみにSLPS_010.80がこの作品のメインプログラムデータなのですが、漫才デモで使われる単語すら
ヒットしなかったため、これはハズレと予測されるため別のデータを見てゆきます。
XA(音源データ)やSTR(動画データ)を省くと残るデータは2つ…PUYO3フォルダの
COMIC.SCR
と
CUTIN.SCR
です。
SCRは間違いなく scenario(シナリオ) の略だと一発で分かります。
CUTIN(カットイン)も響きからすると会話データが格納されていそうですが、
今回は漫才デモを得ることが目的ですので、当然
COMIC(漫才/喜劇)
が対象となります。
2バイト文字を1バイトモードで検索
ぷよSUNでは平仮名以外にも英数・カタカナ・漢字など多種多様の文字が使われており、
確実に1バイト文字ではないことが分かります。
そこで2バイト文字であると仮定して調べていくのですが、
拙作のGCCODEは2バイト文字検索モードが搭載されているものの
ゲームのように独自の文字コードを採用する場合では全く使うことが出来ません。
(PCの文字コードがある意味「異様」でもあるのですが…)。
そこでGCCODEのワイルドカード(不要文字の読み飛ばし)を活用します。
アルルVSドラコ戦の漫才デモは漢字やらカタカナ・キャラ名が入り混じり、
あまりサーチに都合の良い文字列がなかなか見当たりませんでしたが、
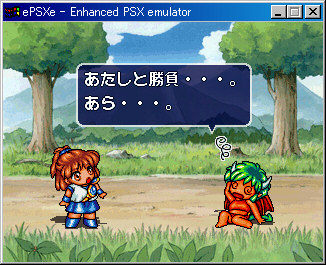
会話後半に一言だけ調べやすそうな会話がありました。
「あたしと」「勝負(漢字はとりあえず後から解析)」「・・・(記号が3つ連なる)」
これは「あたしと」をキーにして、「勝負」と思われる2文字に続いて
「・・・」と同じ数値が3連続で連なってる個所を見つければ良いということになります。
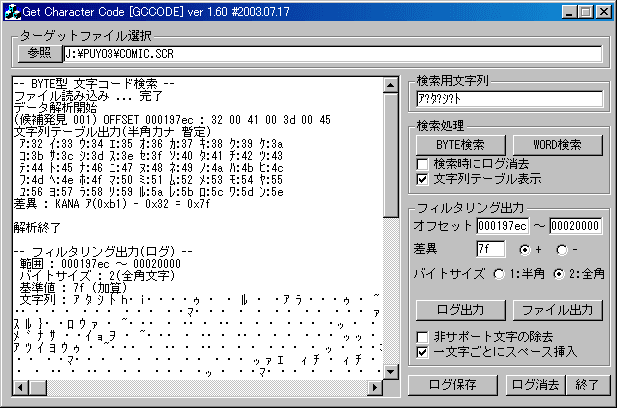
それではGCCODEを立ち上げたら、半角で以下の文字列を入力します。
・検索用文字列
ア?タ?シ?ト
そして「BYTE検索」のボタンをクリックします。
見事に一ヶ所にヒットしました。
今までに無い変な検索用文字列ですが、間に ? をはさむことにより、
強制的に本来2バイトコードをスキップして各文字に定義されたキャラクタ番号のみを
検索対象とすることが出来ます(製作段階では予定していなかった副産物ですが)。
本来の内容と該当オフセット(197EC)周辺のバイナリエディタの値を比較してみると…
あ
た
し
と
勝
負
・
・
・
。
32 00
41 00
3D 00
45 00
E9 00
EA 00
26 00
26 00
26 00
2A 00
文句なしで完璧にパターンが一致しています。
(サーチ時は2桁目の 00 を ? でスキップしているのですね)。
ただし直後に10バイトの 02 FF 04 FF 5A 00 03 FF 08 00 というコードがあり、
その次から2行目の「あら・・・」のデータである 32 00 58 00 26 00 26 00 26 00 が
始まっているのを見ると、この漫才デモを制御するためのスクリプトコードも
含まれたデータであるということが分かります。
コンバートプログラムを組む際にはこのスクリプトコードを無視する、
もしくは改行やセリフ消去部分に対応する処理を行う必要があります。
(私の場合は改行はそのまま、セリフ消去は改行2列で対応します)。
コンバート方法
今までと何ら変わりありません。
「あ=32 00 い=33 00 う=34 00」のようなパターンで並んでいるだけですし、
リトルエンディアンでのデータ格納なので「あ=0032・い=0033・う=0034」と、
ほぼ1バイト文字の処理と同じようにやれば問題ありません。
例えナンバーが0100や0200になったとしても、テーブルを大きくすれば済むことですし、
そんなに難しく考える必要は無いと思われます。
Cソース
VisualC++ 6.0で作ったコンバートサンプルプログラムです。
コンパイル済みのEXEファイルやドキュメント・パターンテーブルも同封しており、
当コンテンツで解説していないCOMIC.SCRの詳細情報なども記載しています。
プロジェクトは Win32 console application の "Hello,World!"アプリケーション を選択し、
丸ごとメインのソースに上書きすればコンパイル&ビルドができます。
Borland C++ Compilerでは1行目の
#include "stdafx.h"
を消去してからコンパイルしてください。
>>コンバータ本体・Cソースのダウンロード
TOPに戻る